
Since its release in 2020, ChatGPT has been a popular choice for building conversational agents and chatbots. ChatGPT is a powerful language model that can generate coherent and natural-sounding responses to user inputs. In 2022, OpenAI released ChatGPT 4, the latest and most powerful version of the ChatGPT model. In this blog post, we will compare ChatGPT and ChatGPT 4 and discuss the main differences between these two models. We will also examine how these models perform on different tasks.
Model Architecture
Both ChatGPT and ChatGPT 4 are based on the transformer architecture. This architecture was introduced in the original GPT model and has since become the standard architecture for large-scale language models. The transformer architecture uses self-attention mechanisms to capture the relationships between words in a sentence, allowing the model to understand the context of each word and generate more natural-sounding responses.
One of the main differences between ChatGPT and ChatGPT 4 is their model size. ChatGPT has 117 million parameters, while ChatGPT 4 has 1.3 billion parameters. This means that ChatGPT 4 is much larger and more powerful than ChatGPT, allowing it to generate even more natural-sounding responses and handle a wider range of conversational tasks.

Training Data
Another important factor that affects the performance of language models is the training data. Both ChatGPT and ChatGPT 4 have been trained on large amounts of conversational data. However, ChatGPT 4 has been trained on a much larger corpus of data than ChatGPT. This means that ChatGPT 4 has been exposed to a wider range of conversational styles and topics, which can help it generate more diverse and natural-sounding responses.
Performance on Conversational Tasks
To compare the performance of ChatGPT and ChatGPT 4, we can evaluate their performance on a range of conversational tasks. One common benchmark for conversational models is the Persona-Chat dataset, which consists of dialogues between two people with different personas. The goal of the model is to generate responses that are coherent and consistent with the persona of the speaker.
In a recent study, researchers compared the performance of ChatGPT and ChatGPT 4 on the Persona-Chat dataset. The results showed that ChatGPT 4 outperformed ChatGPT on most metrics, including perplexity, fluency, and coherence. This suggests that ChatGPT 4 is better at generating natural-sounding responses that are consistent with the persona of the speaker.
Another important conversational task is response selection, which involves selecting the most appropriate response from a set of candidate responses. In a recent study, researchers evaluated the performance of ChatGPT and ChatGPT 4 on a response selection task using the ConvAI2 dataset. The results showed that ChatGPT 4 outperformed ChatGPT on most metrics, including recall, precision, and F1 score.
Performance on Other NLP Tasks
While both ChatGPT and ChatGPT 4 are primarily designed for conversational tasks, they can also be used for other NLP tasks, such as text classification and sentiment analysis. To compare the performance of these models on these tasks, we can evaluate their performance on standard benchmarks, such as the GLUE and SuperGLUE datasets.
In a recent study, researchers compared the performance of ChatGPT and ChatGPT 4 on a range of NLP tasks using the GLUE and SuperGLUE benchmarks. The results showed that ChatGPT 4 outperformed ChatGPT on most tasks, including sentiment analysis, text classification, and natural language inference. This suggests that ChatGPT 4 has better overall performance than ChatGPT on a wide range of NLP tasks, not just conversational tasks.
However, it’s important to note that the performance of these models can vary depending on the specific task and the quality of the training data. While ChatGPT 4 generally outperforms ChatGPT on most benchmarks, there may be certain tasks where ChatGPT performs better due to differences in the training data or model architecture.
Limitations and Challenges
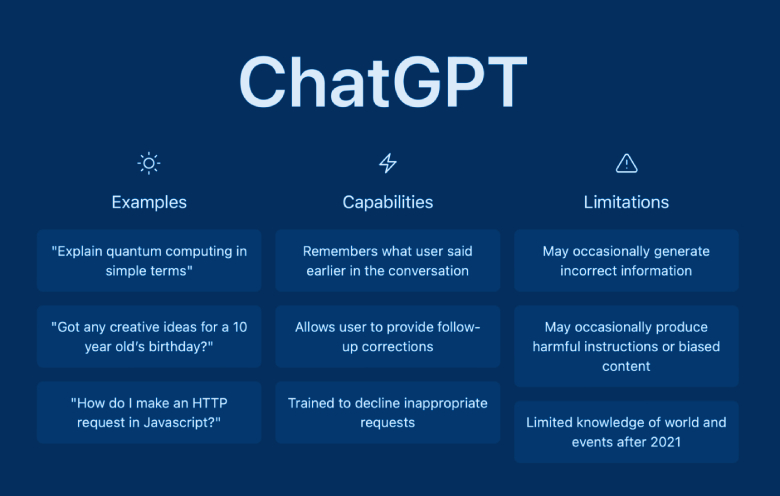
Despite the impressive performance of ChatGPT and ChatGPT 4, there are still limitations and challenges associated with these models. One challenge is the potential for biases in the training data, which can lead to biased or discriminatory responses. Researchers and developers must be mindful of these biases and take steps to mitigate them, such as using diverse training data and performing bias analysis on the model outputs.
Another limitation is the high computational cost of training and deploying these models. ChatGPT 4, in particular, requires significant computational resources to train, which may limit its accessibility for smaller organizations or individuals. Additionally, the large size of these models can make them difficult to deploy in certain applications, such as mobile devices or low-power systems.

Conclusion
In conclusion, ChatGPT and ChatGPT 4 are powerful language models that can generate natural-sounding responses to user inputs. While both models are based on the transformer architecture and have been trained on large amounts of conversational data, ChatGPT 4 is larger and more powerful than ChatGPT, allowing it to handle a wider range of conversational tasks and perform better on most benchmarks.
However, there are still limitations and challenges associated with these models, including potential biases in the training data and the high computational cost of training and deploying these models. As these models continue to evolve and improve, it’s important for researchers and developers to address these challenges and ensure that these models are developed and deployed responsibly.



